
It might be possible to build and run a successful mobile game alone on intuition, but at Kolibri Games, we made the experience that a truly player-centric game that will guarantee long-term success needs data-driven decision-making. The data a games company collects can support its product development, testing, marketing, and monetization. Therefore, data quality, as well as the tech stack behind it, are immensely important to deliver valuable information which directly impacts strategy.
António joined Kolibri Games in 2018 as a Data Engineer and was deeply involved in the evolution of our data platform. In this post, he will explain what our data needs looked like in the past and how we continue to meet them through state-of-the-art tech solutions. Get some inspiration from our learnings to help you elevate your own data setup!
The Evolution of our Data Platform
The year 2016 marked the first time we started to realize that we needed information provided by data. To evaluate if our first game “Idle Miner Tycoon” was meeting our success metrics, both financial and otherwise, we needed to establish a basic form of business reporting to look at our monetization model. Lacking all the necessary data for assessing, we set our objectives to start reporting on In-App Purchases, Ad revenue, crashes and bugs, and game-specific KPIs like retention and sessions.
We implemented the first types of software to support data collection and analysis, starting out with third-party tools from our Ad and Marketing Partners. Though helpful, it turned out that this setup was not flexible enough for our needs and our goal to dig deeper into data to improve our game. Addressing these goals, our tech stack started to grow. With more tools added that reported on analytics, all the data was scattered even more. This led to a lack of transparency, no version control, and no tests or data quality checks.
Add on top the biggest goal to date: To professionalize performance marketing and centralize all the data for business, marketing, and game KPI reporting. How do you build a tool that gathers all the information we need, you might even say, one tool to rule them all? The biggest decision to make was to not rely on another third-party software but to invest in our own solution to centralize the data. This included collecting raw data, building a central data warehouse, and setting up a visualization tool for all involved teams to use.
From Collecting Data to Data-Driven
By gathering data ourselves, we could investigate raw data events and started to run A/B tests in our games. We were collecting a lot of data, but we could not properly analyze it to drive value from all this information. Our product managers could access the data, but they were not able to make or support decisions from it. The goal was to establish more dashboards depicting monetization, progression, and engagement, as well as to improve the performance and stability of the overall platform. And with our team constantly growing, our tech stack expanded as well.
To achieve our goal of becoming a truly data-driven company, we started the Data 2020 initiative. To summarize, the goal of Data 2020 was to make our decisions fully data-driven to unlock our games’ full potential. Our Co-Founder Olli describes the Data 2020 project in more detail here. To base almost all of our decisions for Idle Miner Tycoon on data we needed the tech setup to support this:
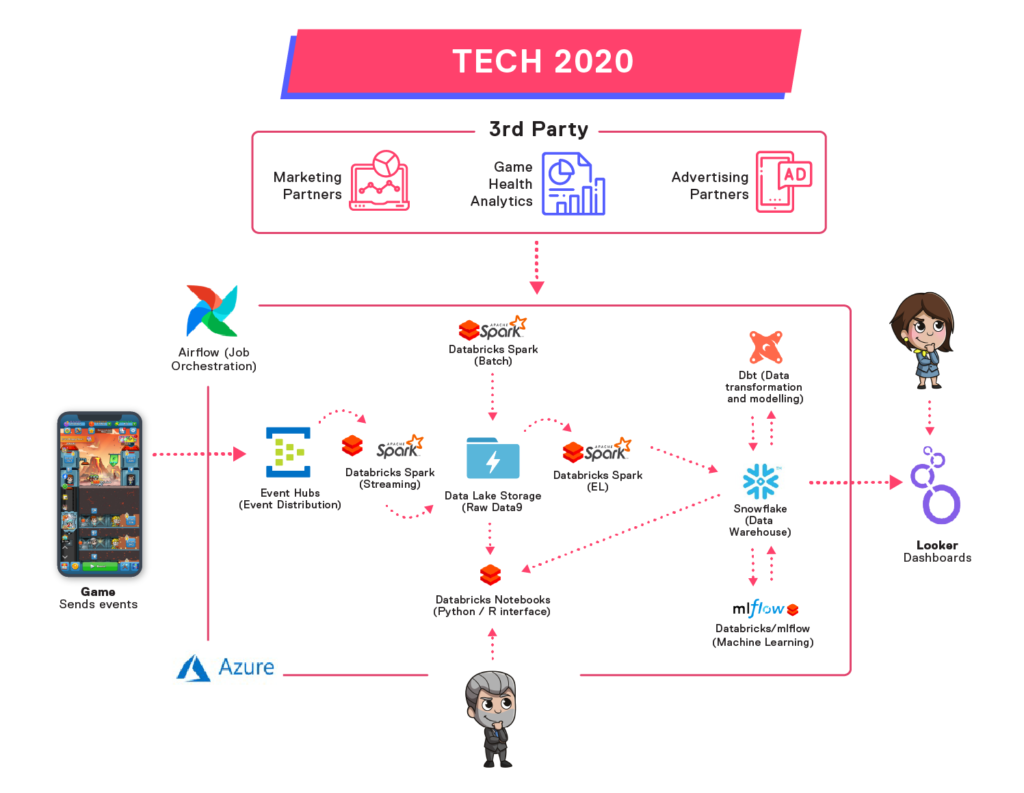
How Does our Data Tech Stack Look Like?
Let me give you a quick rundown:
You can see in the graphic above that it looks a lot different from what we’ve started out with in 2016: We now integrate data into our platform from several data sources by batching new chunks of data every day or streaming it in real-time. Most of our partners provide us with APIs from which we gather the data by using Python notebooks, but our games are the main source of streaming datasets, producing hundreds of millions of events a day.
We ingest the streaming data in Azure Event Hubs and then process it using Spark Structured Streaming. Most of the integrations of the data run in Databricks, which is also the computation platform for other advanced analytics processes like machine learning and A/B Testing evaluations.
All the ingested data lands in our Azure Data Lake Storage. This storage platform receives our data in a raw format without any filtering or enrichment to be further integrated into our data warehouse. For some specific use cases, we also maintain a Databricks Delta Lake layer of access.
Although Data Lake contains all data, it is in our data warehouse where the data takes shape. After a first iteration with an Azure SQL database, we use Snowflake, a cloud-based platform, as our data warehouse. After extracting the data, we load it from our Data Lake into Snowflake while still keeping it in a raw format. In Snowflake, we filter, clean, and structure the data so that it is available for all the data developers to build their data models. They build these data models by performing heavy joins, enrichments, and aggregations. The models can then be used by our Business Intelligence tool or act as a starting point for ML models. With this, the transformations are complete.
DBT is our data model management tool. Its purpose is to help us transform all the data within our data warehouse and manage all the dependencies between the transformed data sets. It also gives us the ability to test our data models to make sure we deliver high data quality.
All of these processes are supported by Airflow, an orchestration tool. When we define dependencies between execution tasks, Airflow ensures that the order of execution is followed, and it also notifies us in case of execution failures. We use it to trigger all types of workloads, from Databricks jobs to DBT model runs.
Finally, we use Looker as our BI visualization tool to present data to everyone in the company. In Looker, the data is available for exploration and for reporting all the transformed data in our data warehouse.
DATA 2021 – What Comes Next?
Our Data goals for 2021 focus on Data Quality, System Robustness, and a Data Democratization culture. This means in more detail:
Data Quality means for us that data is only valuable when it is correct. We need to build the tools and the process that can guarantee data quality and gain the trust of our users so that all decisions we are taking are made with confidence. This includes improving our development testing frameworks and to define the staging environments we work on, from development to production. To monitor and measure data quality we are also merging our tools and processes to enhance data validation and alerting.
With robust systems, we ensure a high level of data quality. Our systems need to be capable of fast recovery and mitigation. We achieve this by following state-of-the-art engineering practices to manage our cloud infrastructure.
Data Democratization means that not only the data team but everyone at Kolibri Games has easy access to the platform and the data they need. We want to empower all data platform users to integrate and process more data so that more decision-making can be backed by the data provided.
Not to forget, that our data platform is the basis of support for our A/B Tests, Marketing, and also for our LiveOps platform, which is in development right now.
What Are Learnings from our Data Evolution?
To summarize, our Data evolution is an ongoing journey. It’s important to always stay agile and flexible for new solutions. We hope that sharing our learnings will help you with building and evolving your Data tech stack – you can check out our most important learnings in the graphic below:

You can see, we’ve come a long way over the years evolving our data goals and setup, and it’s an ongoing process to identify problem areas and work on innovative solutions. What a mission!
But we would not have achieved over 100 million downloads with our games, had we not been ambitious from the start.
If bringing our Data Platform to the next level sounds like the right mission for you, have a look at our open positions here.